

Que o ElasticSearch é uma ferramenta incrível,
você já deve saber ou ao menos ouvido falar. O não te disseram é que, mesmo com
uma resiliência incrível e elasticidade que está cravada no nome, o ES,
se não acompanhado de perto, pode criar vários problemas. Principalmente
porque normalmente ele é o cara que vai receber imensas
porradas
de indexação e deve ser capaz de executar analytics/searches num piscar de
olhos para se dar o real valor como Data Store
distribuído.

Shay: era pra ser um livro de receitas pra esposa…
❤
Logo, pra ficar ligado no que ocorre dentro do seu
cluster,
sem ter que ficar chamando as
APIs
— muito úteis em várias situações— você precisa de ferramentas de monitoramento
que lhe dê respostas rápidas e visualizações simples de se entender.
Por que não usar o Monitoring (Marvel)?

Marvel era um nome tão mais legal :(
O primeiro grande motivo de não sugerir o Monitoring, *antigo *Marvel,
plugin de monitoramento que a própria Elastic
disponibiliza por meio do
X-Pack, é que ele completão é pago
e caro. :/
Até tem uma versão free, que você consegue com a licença
básica,
mas ela é limitada drasticamente após 30 dias. O Marvel utiliza a própria API
do
Elastic
para pegar dados do cluster e indexa tais retornos no próprio ES, nos índices
.monitoring. Estes índices são
rotacionados
de 7 em 7 dias. Então se alguma coisa ocorreu no seu cluster há mais de uma
semana, já era…
$> sudo service elasticsearch stop
O segundo motivo é que, se você já roda um cluster de ES em produção, vai
ter um trabalho do cão pra instalar o Monitoring. Como ele roda como parte do
X-Pack, é necessário sua instalação em todos nós do
cluster.
E isso envolve um** fucking full cluster
restart!***
*Cara… com 1 nó em produção já é MUITO cagaço fazer isso, imagina com 10 nós com
10Tb de dados e 1bi de docs e 10k indexações por minuto?! Não, você não vai
querer fazer isso!
Use o Cérebro!
Com esse tanto de API REST supimpa que o ElasticSearch
nos oferece, é claaaro que alguém ia começar a construir um negócio
open-source pra galera. Esse projeto é o
Cérebro! O inexorável Leonardo
Menezes começou por conta própria fazer um
p#$% projeto de monitoramento e administração do ElasticSearch, o
antigo Kopf. Tudo usando as
facilidades da API do ES e seu profundo conhecimento de JS e
Scala! ❤
Funcionalidades
No Cérebro temos 2 telas de monitoramento:
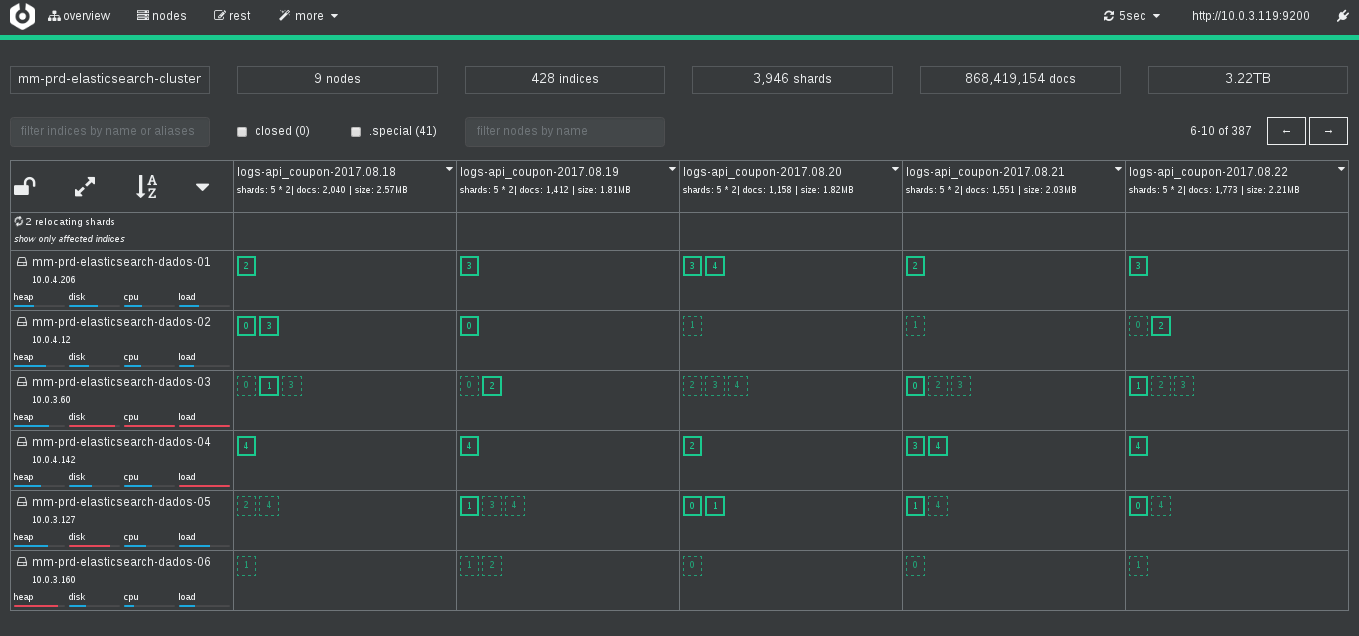
- Overview: traz dados de **todos **índices e quais nós estes tem
shards
e réplicas alocadas. Nessa tela você pode fazer roteamento de
shards
com apenas um fucking clique:
- Nodes: traz as estatísticas de sistema dos nós, como load, cpu, espaço
em disco e uptime:
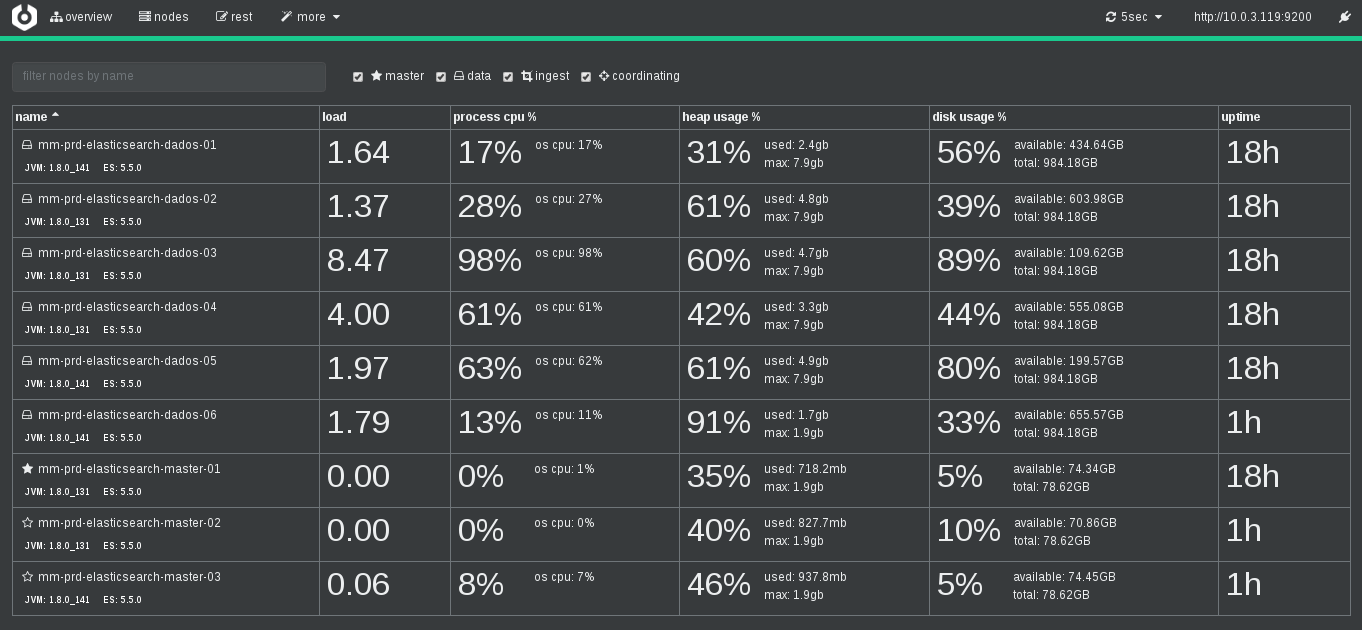
Além delas tem a sessão REST, que é a mesma coisa do DevTools do Kibana, e More: com ferramentas administrativas avançadas como gerenciamento de snapshots, aliases, cluster settings
e etc — muito cuidado por aí!
Instalação
É incrível, não é?! E como instalar esse negócio lindo? Simples demais:
- Baixar uma versão do Cérebro, descompactar e rodar:
wget https://github.com/lmenezes/cerebro/releases/download/v0.7.0/cerebro-0.7.0.zip
unzip cerebro-0.7.0.zip .
./cerebro-0.7.0/bin/cerebro
- Acessar
https://localhost:9000e apontar pra algum nó de seu cluster, de
preferência um mais sussa, como um nó master elegível ou um client/coordinator – *https://meu.no.sussa:9200/.
Pronto! Seu cluster tá lá, intacto, sem restart nenhum.

Pois é… a gente ainda não tem os gráficos de memória, indexações, buscas e JVM,
muito importantes pra um bom monitoramento. A gente podia coletar isso tudo com
Logstash e visualizar no
Kibana, que é o que o Marvel faz, né.
Mas vai dar um traaaampo… :/
New Relic: uma Relíquia de Monitoramentos

Agora eu te pergunto: pra quê cê vai se preocupar em coletar seus próprios
logs e fazer dashboards se alguém já faz isso muito melhor que você?
Duvida?! Ah… então venha ver o New Relic: maravilha dos
monitoramentos! Várias empresas mundialmente
conhecidas usam o New Relic para
monitorar seus sistemas, inclusive a
MaxMilhas.
Ele tem
de
tudo! Desde tracking transação a transação de
aplicações web e non-web (como
sistemas de filas, crons…) até plugins
que qualquer um pode fazer. É aí que resolvemos nosso problema.
Plugin do ElasticSearch
No New Relic, temos um plugin que faz o todos os monitoramentos do Marvel e
melhor: com persistência de 3 meses. Além das informações básicas de numero de
requests e total de documentos, ele traz detalhes dos hosts como I/O, Memória
e CPU, Thread
Pool
das Requisições de Busca e Indexação, dados do Heap da
JVM
e mais. Além de poder filtrar por nós, e escolher as faixas temporais dos
gráficos:
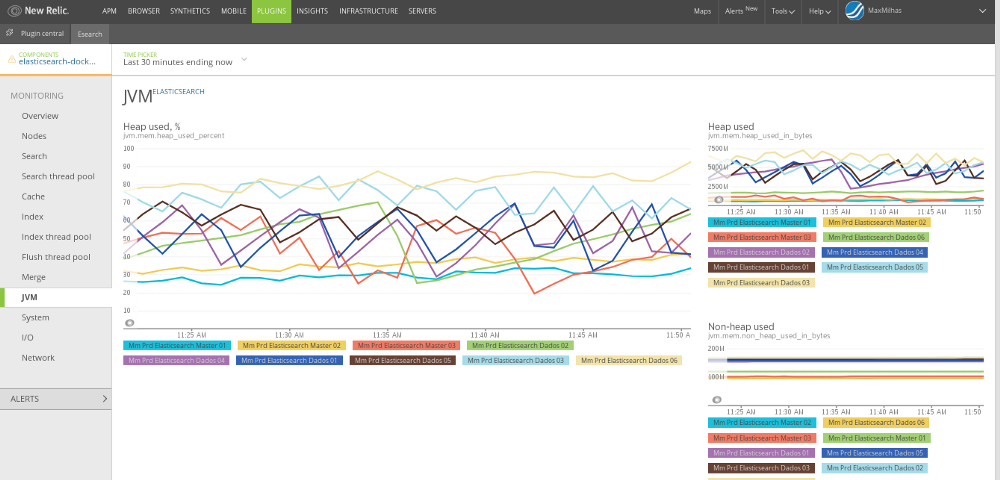
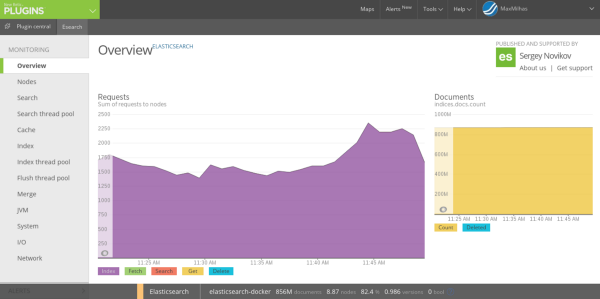
Única coisa que você precisa é do coletor do New Relic rodando em algum lugar
que consegue acessar uma máquina do seu cluster, para ele fazer requisições
para as APIs do ES. Sua
instalação é também muito
simples e não requer nenhuma ação no cluster. Tem um Docker que roda
tudo:
docker run -e "ES_HOST=<nó_sussa_do_cluster" -e "NEW_RELIC_LICENSE_KEY=" s12v/newrelic-elasticsearch
Obviamente, sugiro que você coloque tanto o coletor do New Relic quanto o
Cérebro em máquinas separadas do cluster: primeiro pra você não ficar no
escuro nas horas do disastres e segundo para não contaminar as métricas.
Ah… mas o New Relic é pago… :|
Sim, é. Mas é BEM mais barato que a licença do X-Pack ou do que você construir
tudo na mão, até usando a stack ELK. O New Relic tem um free tier bem
generoso.
Antes de sair testando e construindo ferramentas escaláveis, é fundamental que
você avalie formas de mantê-las, pois com certeza vão crescer algum dia.
Vai sempre ter um ponto de inflexão, onde não há como utilizar só os bons e
velhos ps | grepe top para gerir sua infra.
Curtiu essa dica? Então compartilhe e recomende esse artigo pros seus colegas.
Quer sugerir um outro assunto? Comente aí embaixo! E não deixe de me seguir para
acompanhar mais paradas legais sobre dados! Abração!