Muito ja foi falado sobre DOM e posso estar sendo repetitivo aqui, mas é importante falar deste assunto que em dias de manipulação pesada de seletores, percebo que pouca atenção é dada. Temos muita literatura boa sobre o assunto mas muitas vezes o foco acaba sendo o novo plugin que saiu e faz mais-do-mesmo-no-front-end-só-que-mais-fácil (E se você tiver sorte ele é free).
Entender realmente como um navegador funciona é importante, e garante seu entendimento do real dos problemas que está enfrentando no código que está implementando. Tem mais! Criar um código que manipula o layout (leia-se DOM) fica mais fácil, é uma relação win-win.
Criado pelo W3C, O DOM é uma multi-plataforma que representa como as marcações em HTML, XHTML e XML são organizadas e lidas pelo navegador que você usa. Uma vez indexadas, estas marcações se transformam em elementos de uma árvore que você pode manipular via API – que é o que fazemos quando usamos programas ou scripts para alterar funcionalidades de uma página: conteudo, estrutura ou folha de estilo.
Um pouco de história
Não tem graça falar sobre o assunto sem mostrar como ele surgiu. Isso só reforça ainda mais a importância de conhecermos bem o assunto pois mostra sua relevância (e porque falar de browser wars é bem legal, apesar de evidenciar os cabelos brancos).
Netscape e Microsoft guerreavam com Netscape 2 e IE3.0 lá em 1996 e enquanto a Netscape lançava o Javascript a Microsoft lançava o JScript. A diferença entre um e outro não é nada mais além do nome – acredite! Por razões comerciais devido as “sangrentas” browser wars as empresas decidiram adotar nomes diferentes para a mesma coisa – que na verdade era (e continua sendo) o ECMAScript, a linguagem que comecou a ser criada em 1994 quando o W3C colocou na mesma mesa as duas empresas e várias outras para desenvolver um padrão para linguagens de script para os navegadores. Javascript, JScript e ActionScript não são nada mais que dialetos de ECMAScript.
Texto: É o texto que vai entre os elementos. Todo o conteúdo das tags (Isto é um text node
). O nó de Texto guarda basicamente texto puro, que pode ser renderizado ou trabalhado via script.
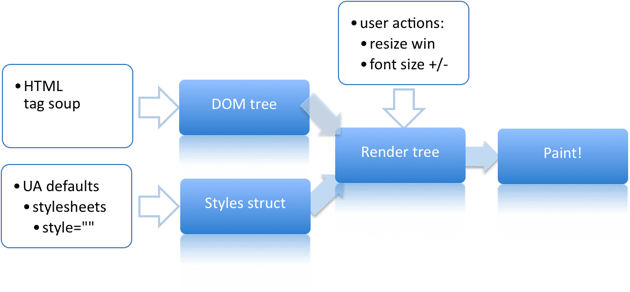
A Render Tree

Como a render tree é montada
A Render Tree é a parte mais importante do processo de renderização. Bem parecida com a árvore DOM, cada objeto corresponde a nós de Documentos, Elementos ou Texto. A diferença é que q Render Tree possui tambem objetos que não possuem nós na árvore DOM, como scripts e folhas de estilos.
O processo de criação da Render Tree passa pelos seguintes passos:
-
Attachment: Após finalizar o parse do DOM e a criação de seus nós, os navegadores chamam um método chamado attach para começar a renderização. O attach adiciona primeiramente as folhas de estilo a árvore DOM e começa a estilização da página. Um bom exemplo é o uso das propriedades CSS display x visibility: Caso um elemento da árvore DOM tenha uma propriedade display:none, este elemento (e seus nós filhos) não será criado na Render Tree. Ao contrário do uso de visibility:hidden, que vai renderizar o elemento na árvore, porém ele irá remover (ou adicionar quando visibility:visible) via Repaint as cores (ou propriedades) que formam este elemento. Vale lembrar também que este processo de attach é top down, criando sempre inicialmente os nós parent e depois seus descendentes (nós filhos). (Para saber mais sobre Repaint e Reflows, veja este outro artigo)
-
RenderStyle.h: Durante o processo de attach um método é criado, o RenderStyle.h que vai guardar objetos de referência com cada uma das propriedades CSS do documento. O nó criado no DOM é verificado no documento de CSS e caso existam propriedades que incidam naquele elemento, ela é aplicada. Esta propriedade fica salva dentro da Render Tree até que ela seja destruída ou que este valor seja alterado por algum script.
-
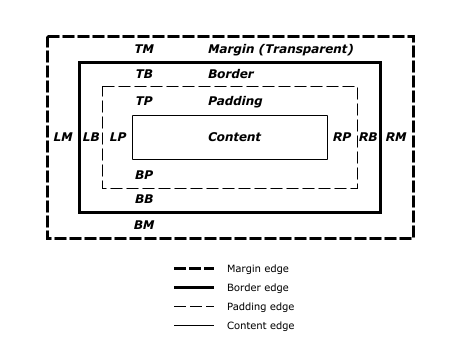
CSS Box Model: Após o método RenderStyle ser criado, ele é acessado via RenderObject. O Box model é usado para posicionar um elemento dentro da página, oferecendo suporte para o conteúdo, padding, bordas e margens que envolvem este elemento
Destruindo (ou atualizando) a Render Tree
A Render Tree é destruída quando nós da árvore DOM são removidos, causando a necessidade de um novo parse no DOM, ou quando uma tab do navegador com a árvore DOM usada é fechada. Após o refresh da árvore DOM, todo o processo acima é refeito, com attach chamando o RenderStyle, que montado chama o método style() do RenderObject que acessa o CSS BOX model.
Como os navegadores interpretam todos estes elementos criados por DOM e Render Tree antes de aplicar o estilo?
Todo navegador tem uma lista de elementos HTML suportados. Quando o seu markup possui tags presentes na lista, a árvore DOM é montada e o processo de attachment começa logo na sequência e os estilos são aplicados, dando continuidade a criação da Render tree.
O grande problema é que cada navegador tem a sua própria lista, que trata situações similares de maneiras diferentes. Obviamente já sabemos que o navegador que mais apresenta problemas para as situações acima é o Internet Explorer, mas acredite, todos os navegadores apresentam problemas quando um elemento não está em sua lista de elementos permitidos, e precisa de um trabalho para fazer tudo acontecer na Render Tree como deve ser feito.
Elementos fora desta lista são tratados como Elementos desconhecidos. E eles são uma grande fonte de problemas:
-
Como estilizar este elemento?Por exemplo, a tag
tem por padrão espacamento no topo e bottom,
possui uma indentação automática adicionando uma margem à esquerda ou tem uma fonte maior que o
por ser um cabeçalho. Tudo isso esta padronizado, mas como cuidar de algo que não existe?
-
Como este elemento deve aparecer na árvore DOM?Os navegadores também possuem uma lista que mostra quais elementos podem ser filhos de outros elementos. Por exemplo, se você adiciona por engano no seu markup
o segundo paragrafo implicitamente fechará o primeiro
, fazendo que os dois elementos sejam irmãos (no mesmo nível na árvore DOM) e nao como nós filhos como de maneira linear pode parecer. Porém se vc adiciona um
, este paragrafo inicial não será fechado, porque o navegador permite que seja filho de elementos de paragrafo, fazendo assim o ser nó filho de
Para elementos desconhecidos, a ideia é não estilizar. Caso queira algum estilo em elementos desconhecidos, você deve colocá-lo no nó acima (se necessário um wrapper), para fazer com que ele herde o estilo.
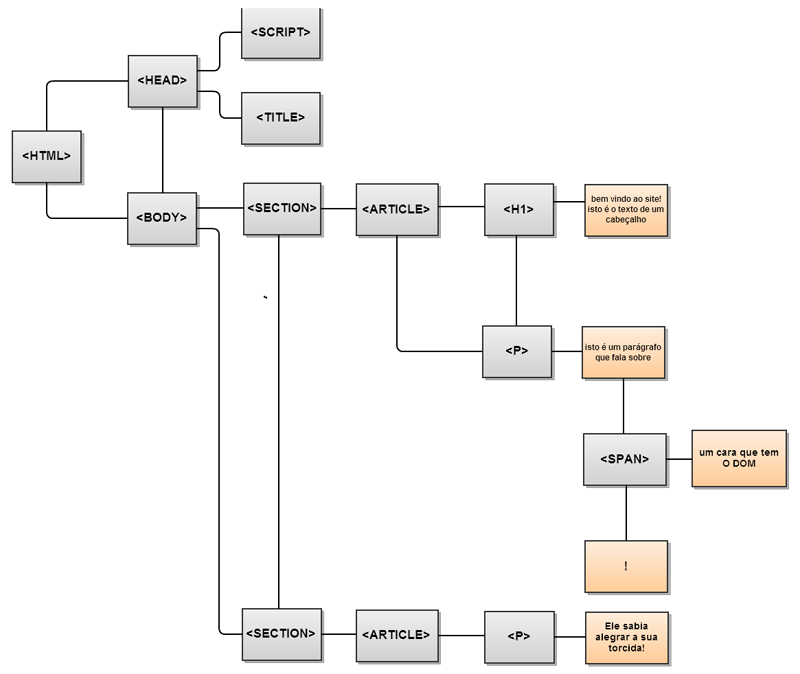
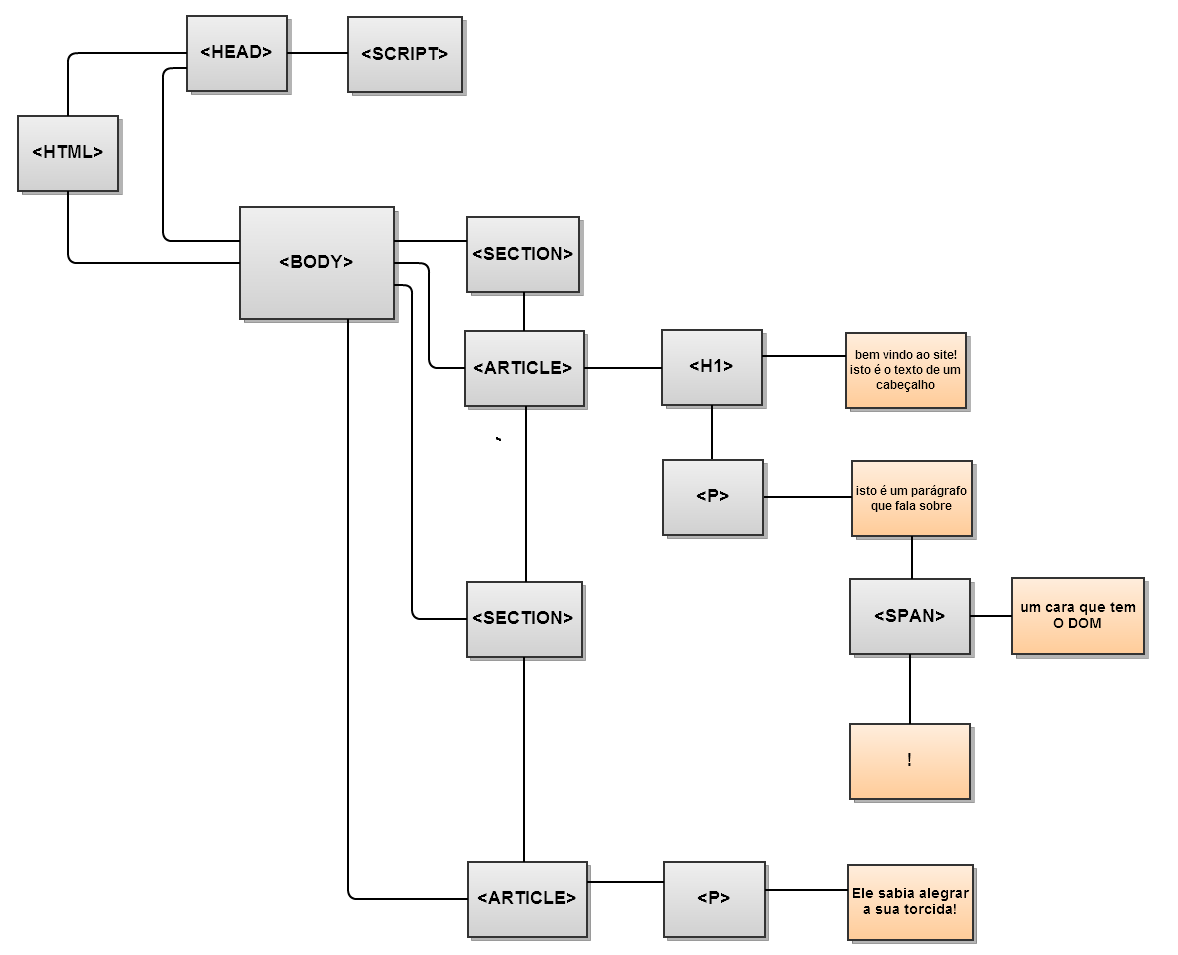
Perceba a sutileza de como isso funciona. Os dois diagramas mostram uma árvore DOM, montada por um navegador suporte HTML5 nativo e o Internet Explorer 8 (navegadores que não suportam HTML5 tem funcionamento semelhante):
Arvore DOM com suporte HTML5
Arvore DOM IE e outros navegadores sem suporte HTML5
É por essas e outras que a gente usa o modernizr, o HTML5shiv ou um simples document.create(“SECTION”) / document.create(“ARTICLE”). E é isso que acontece quando navegadores interpretam elementos desconhecidos. Eles desconsideram o nó real aonde o elemento está, e o reconhece como filho de . E por favor, sem trocadilhos com o filho dos outros.
Ver como uma árvore DOM é montada e como a Render tree é feita nos dá idéia do quão importante é ter um documento semântico. Realmente semântico. Uma vez entendidos os conceitos, a manipulação e a programação dos elementos fica mais fácil.
E você começa a entender como os navegadores funcionam.
Referências
-
Entendendo os Reflows por Alysson Franklin
-
Modernizr para suporte HTML5
-
HTML5shiv para suporte HTML5
-
Browser Wars pela Wikipedia
-
ECMAScript pela Wikipedia
-
Javascript pela Wikipedia
-
JScript pela Wikipedia
-
CSS Box model pelo W3C